Specs, not prompts: from harness engineering to hive mind
Spec-driven AI orchestration is the architecture that compounds at portfolio scale, not prompt engineering. The infrastructure shift parallels Terraform for infrastructure, declarative CI/CD, and Kubernetes for containers.
Blake Aber · Predicate Ventures · 2026
What is harness engineering
Anthropic's engineering team recently published work on infrastructure for long-running AI applications. Their claim: "the infrastructure around the model matters as much as the model itself."
They call this discipline harness engineering. It covers context management, tool integration, verification loops, and resilience patterns. The key insight: two products using identical LLMs can produce vastly different outcomes depending on their supporting architecture.
Their research identified production challenges:
- Context limitations. Naive compression loses important information. Work with Claude Sonnet 4.5 revealed performance degradation with accumulated compacted context, requiring full resets to restore quality.
- Over-ambition in agents. Without structured decomposition, models attempt complex tasks in single attempts. Outputs appear complete but aren't.
- Unreliable self-evaluation. Agents confidently praise mediocre work. External verification (what Anthropic calls the generator-evaluator pattern) is necessary.
These solutions work for single agents and humans. Multi-agent scenarios (five agents with different tools and shared budgets) compound the coordination overhead nonlinearly.
The infrastructure gap
Shipped agent systems demonstrate that LLMs can write code, analyze data, and draft documents. But teams rebuild scaffolding constantly. Each new workflow requires re-engineering context flow, output verification, and budget enforcement. Knowledge from previous projects doesn't transfer.
Verification becomes human-intensive. Teams handle five workflows daily through manual review. Fifty workflows daily? The system breaks.
Context costs compound exponentially in multi-agent chains. Forwarding Agent A's complete output through Agents B and C, where information silently truncates at limits, represents standard practice in most frameworks today.
Eighteen months of prompt engineering results
Industry teams achieved real systems through careful prompt design, retrieval-augmented context, and chain-of-thought decomposition. But a ceiling exists.
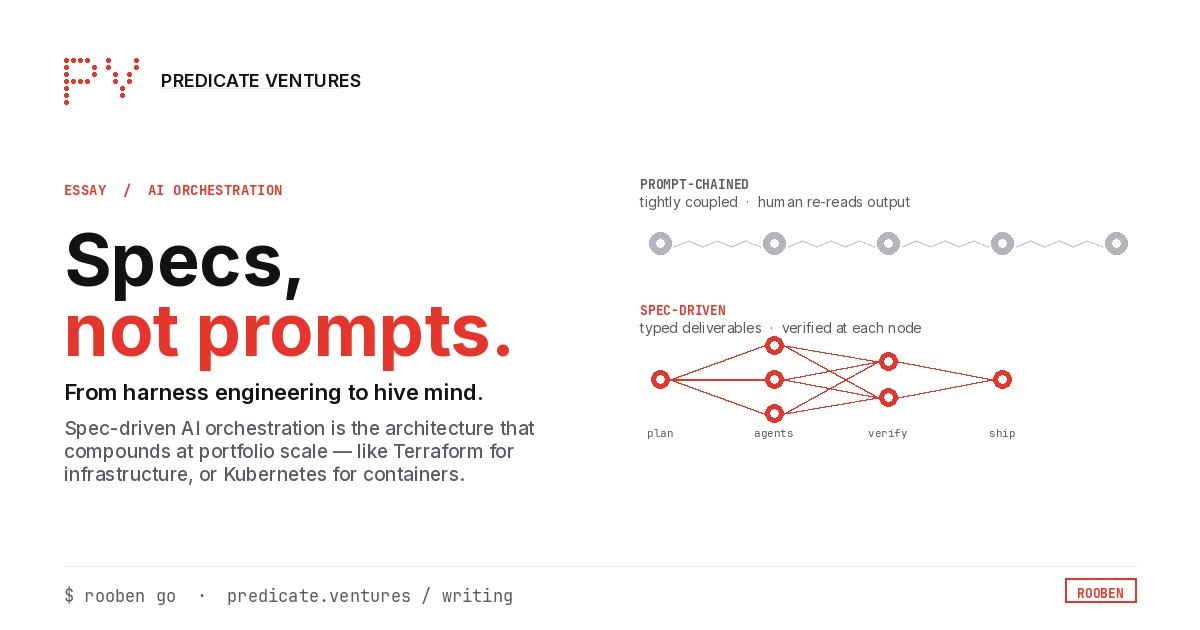
Output distributions resist narrowing like test suites do. Verification requires human re-reading. Without external evaluation, quality remains aspirational. Context becomes hidden cost. Redundant information flows through agent chains while critical details get truncated.
The harness couples tightly to specific workflows. Changing verification strategies or budgets requires complete rewrites, not reconfiguration. This is precisely what Anthropic identifies as problematic: teams build bespoke harnesses repeatedly.
The specification as coordination mechanism
If harness engineering is the discipline, specifications function as the executable contract.
What if multi-agent systems accepted specifications instead of prompts? Not rigid schemas requiring engineering expertise to write, but structured contracts generated from plain English defining:
- Deliverables: with types (code, documents, APIs, infrastructure)
- Verification: acceptance criteria with priorities and methods (test runners, LLM judges, or combinations)
- Agent assignments: capability matching, concurrency limits, retry budgets
- Cost controls: hard limits on tokens, USD, wall-clock time, concurrent agents
Generated from natural language and reviewed before execution, specs become machine-readable contracts that orchestrators execute against. The pattern mirrors Terraform's plan-before-apply workflow.
Three structural changes
Context becomes structured rather than concatenated
Agents receive task descriptions, acceptance criteria, typed outputs from upstream dependencies (artifacts, not full transcripts), and feedback from prior attempts if retrying.
Context assembly is priority-ordered and budget-aware. Under pressure, low-priority sections drop first. Task descriptions and acceptance criteria remain intact. Agents receive less but more relevant context, reducing token usage while improving quality.
Verification integrates into contracts
Verification becomes mandatory and composable at every task graph node. Each deliverable has acceptance criteria with specified verification methods:
- Test verification
- LLM judge evaluation with structured feedback
- Chained verification with short-circuit failure modes
When verification fails, the system stores expectations versus results and judge suggestions. That structured feedback injects into retries: not generic "try again" prompts but specific improvement guidance.
Orchestration becomes declarative
Coordination logic (ordering, dependencies, dispatch, failure handling) lives in application code under prompt-based systems. Spec-driven systems generate task graphs from specifications. The planner handles decomposition. Dependency graphs manage ordering. Budget trackers enforce limits. Circuit breakers prevent cascading failures.
This pattern mirrors successful infrastructure shifts: Terraform for infrastructure declaration, declarative CI/CD pipelines, and Kubernetes for container orchestration.
Economic impact
Multi-agent orchestration costs escalate with naive context handling. Five-task sequential chains consume 3–4x tokens of actual useful generation.
Spec-driven context changes the economics:
- Priority-ordered assembly delivers only necessary information
- Typed dependency outputs forward artifacts rather than generation transcripts
- Budget-aware truncation drops lower-priority content first
- Cache-friendly consistent spec prefixes improve prompt caching hit rates
A nine-task workflow across four agents operates for under $1, not because models are cheap, but because context remains efficient.
Cost visibility matters equally. Per-agent and per-model token tracking enables actionable insights like identifying that test-engineer agents consume 40% of budgets while producing 20% of deliverables.
Multimodal provider support
Rooben is the open-source spec-driven orchestrator I maintain (github.com/blakeaber/rooben). It is the working reference implementation for the architecture described above.
Most AI tools hardwire to single vendors, trapping workflows in ecosystems. Rooben implements an LLMProvider protocol: minimal interfaces any backend implements. Current support includes Anthropic, OpenAI, AWS Bedrock, and Ollama for local models, each with built-in cost tracking.
Mix providers within single workflows: Claude for planning, GPT-4o for code generation, local models for sensitive operations. StateBackend protocols work similarly, defaulting to local JSON while supporting S3, databases, or custom backends.
When model capabilities shift, as they inevitably will, swap one configuration line. Specs transfer. Verification criteria transfer. Learning history transfers. Investments compound regardless of current leading models.
Practical implementation
The command rooben go "Build a REST API with CRUD endpoints, input validation, tests, and a Dockerfile" generates a specification for review and approval.
Execution proceeds through:
- Specification decomposition into task graphs
- Structure validation (no cycles, orphaned tasks, missing dependencies)
- Parallel task dispatch to agents
- Structured context delivery (only necessary information)
- Output verification via test runners and LLM judges
- Structured feedback injection for failed task retries
- Cost reporting showing per-agent, per-model token usage
The system stays protocol-based throughout: swappable LLM providers, state backends, verifiers, planners, and agents via structural typing without framework lock-in or inheritance requirements.
Future architecture
Current open-source capabilities handle flat fan-out: planners spawn 3–5 agents working task graphs in parallel.
Next phases ship in Rooben Pro, the commercial extension currently on a waitlist. Via the A2A (Agent-to-Agent) protocol in Rooben Pro, agents spawn sub-agents. A research lead receives tasks, writes sub-specifications, dispatches specialized workers, verifies output, and reports upward. Agent trees, rather than flat pools.
Specs compose naturally: parent spec deliverables become child spec inputs. Organizational layers in Rooben Pro map team members to departments and roles with tracked outcomes across workflows, enabling the system to learn contextual definitions of quality.
The gradient progresses from individual developers using the CLI for single workflows to armies of specialized agents mapped to organizational roles, each refining specifications over iterations. The 50th workflow execution measurably improves over the first.
Moving forward
Rooben remains open-source with a public roadmap covering expanded agent transports, cross-run learning, marketplace integrations, and hierarchical orchestration. Detailed technical comparisons and harness engineering guidance are in the project documentation.